Originally published as part of the Go Advent 2018 series
Overview
Apache Beam (batch and stream) is a powerful tool for handling embarrassingly parallel workloads. It is a evolution of Google’s Flume, which provides batch and streaming data processing based on the MapReduce concepts. One of the novel features of Beam is that it’s agnostic to the platform that runs the code. For example, a pipeline can be written once, and run locally, across Flink or Spark clusters, or on Google Cloud Dataflow.
An experimental Go SDK was created for Beam, and while it is still immature compared to Beam for Python and Java, it is able to do some impressive things. The remainder of this article will briefly recap a simple example from the Apache Beam site, and then work through a more complex example running on Dataflow. Consider this a more advanced version of the official getted started guide on the Apache Beam site.
Before we begin, it’s worth pointing out, that if you can do your analysis on a single machine, it is more likely faster, and more cost effective. Beam is more suitable when your data processing needs are large enough they must run in a distributed fashion.
Table of Contents
Concepts
Beam already has good documentation, that explains all the main concepts. We will cover some of the basics.
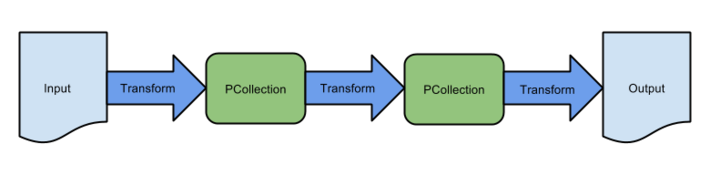
Pipeline stages
A pipeline is made up of multiple steps, that takes some input, operates on that data, and finally produces output. The steps that operates on the data are called PTransforms (parallel transforms), and the data is always stored in PCollections (parallel collections). The PTransform takes one item at a time from the PCollection and operates on it. The PTransform are assumed to be hermetic, using no global state, thus ensuring it will always produce the same output for the given input. These properties allow the data to be sharded into multiple smaller dataset and processed in any order across multiple machines. The code you write ends up being very simple, but is able to seamlessly split across 100s of machines.
Shakespeare (simple example)
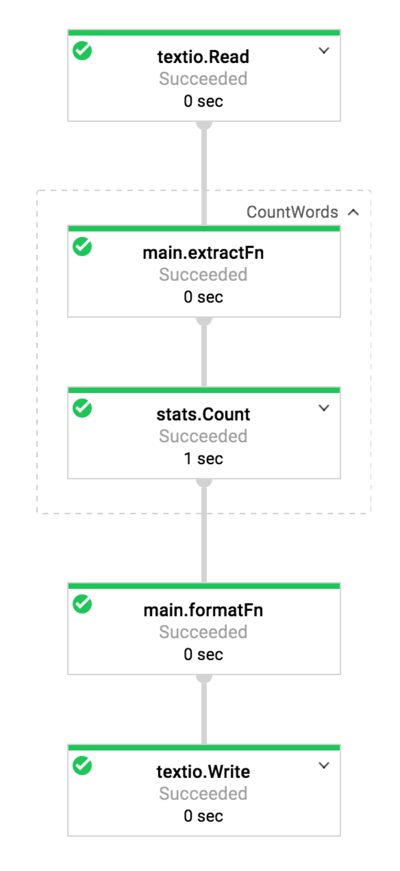
A classic example is counting the words in Shakespeare. In brief, the pipeline counts the number of times each word appears across Shakespeare’s works, and outputs a simple key-value list of word to word-count. There is an example provided with the Beam SDK, and along with a great walk through. I suggest you read that before continuing. I will however dive into some of the Go specifics, and add additional context.
The example begins with textio.Read, which reads all the files under the shakespeare directory stored on Google Cloud Storage (GCS). The files are stored on GCS, so when this pipeline runs across a cluster of machines, they will all have access. textio.Read always returns a PCollection<string> which contains one element for every line in the given files.
lines := textio.Read(s, "gs://apache-beam-samples/shakespeare/*")
The lines PCollection is then processed by a ParDo (Parallel Do), a type of PTransform. Most transforms are built with a beam.ParDo. It will execute a supplied function in parallel on the source PCollection. In this example, the function is defined inline and very simply splits the input lines into words with a regexp. Each word is then emitted to another PCollection<string> named words. Note how for every line, zero or more words may be emitted, making this new collection a different size to the original.
splitFunc := func(line string, emit func(string)) {
for _, word := range wordRE.FindAllString(line, -1) {
emit(word)
}
}
words := beam.ParDo(s, splitFunc, lines)
An interesting trick used by the Apache Beam Go API is passing functions as an interface{}, and using reflection to infer the types. Specifically, since lines is a PCollection<string> it is expected that the first argument of splitFunc is a string type. The second argument to splitFunc will allow Beam to infer the type of the words output PCollection. In this example it is a function with a single string argument. Thus the output type will be PCollection<string>. If emit was defined as func(int) then the return type would be a PCollection<int>, and the next PTransform would be expected to handle ints.
The next step uses one of the library’s higher level constructs.
counted := stats.Count(s, words)
stats.Count takes a PCollection<X>, counts each unique element, and outputs a key-value pair of (X, int) as a PCollection<KV<X, int>>. In this specific example, the input is a PCollection<string>, thus the output is PCollection<KV<string, int>>
Internally stats.Count it’s made up of multiple ParDos, and a beam.GroupByKey, but it hides that to make it easier to use.
At this point, the counts of each word has been calculated, and the results are stored to a simple text file. To do this the PCollection<KV<string, int>> is converted to a PCollection<string>, containing one element for each line to be written out.
formatFunc := func(w string, c int) string {
return fmt.Sprintf("%s: %v", w, c)
}
formatted := beam.ParDo(s, formatFunc, counted)
Again a beam.ParDo is used, but you’ll notice the formatFunc is slightly different to the splitFunc above. The formatFunc takes two arguments, a string (the key), and a int (the value). These are the pairs in the PCollection<KV<string, int>>. However, the formatFunc does not take a emit func(...) instead it simply returns a type string.
Since the PTransform outputs a single line for each input element, a simpler form of the function can be specified. One where the output element is just returned from the function. The emit func(...) is useful when the number of output elements differ to the number of input elements. If its a 1:1 mapping a return makes the function easier to read. As above this is all inferred at runtime with reflection when the pipeline is being constructed..
Multiple return arguments can also be used. For example, if the output was expected to be PCollection<KV<float64, bool>>, the return type could be func(...) (float64, bool).
textio.Write(s, "wordcounts.txt", formatted)
Finally textio.Write takes the formatted PCollection<string> and writes it to a file named “wordcounts.txt" with one line per element.
Running the pipeline
To test the pipeline it can easily be run locally like so:
go get github.com/apache/beam/sdks/go/examples/wordcount
cd $GOPATH/src/github.com/apache/beam/sdks/go/examples/wordcount
go run wordcount.go --runner=direct
To run in a more realistic way, it can be run on GCP Dataflow. Before you do so, you need to create a GCP project, create a GCS bucket, enable the Cloud Dataflow APIs, and create a service account. This is documented on the Python quickstart guide, under “Before you begin”.
export GOOGLE_APPLICATION_CREDENTIALS=$PWD/your-gcp-project.json
export BUCKET=your-gcs-bucket
export PROJECT=your-gcp-project
cd $GOPATH/src/github.com/apache/beam/sdks/go/examples/wordcount
go run wordcount.go \
--runner dataflow \
--input gs://dataflow-samples/shakespeare/kinglear.txt \
--output gs://${BUCKET?}/counts \
--project ${PROJECT?} \
--temp_location gs://${BUCKET?}/tmp/ \
--staging_location gs://${BUCKET?}/binaries/ \
--worker_harness_container_image=apache-docker-beam-snapshots-docker.bintray.io/beam/go:20180515
If this works correctly you’ll see something similar to the following printed:
Cross-compiling .../wordcount.go as .../worker-1-1544590905654809000
Staging worker binary: .../worker-1-1544590905654809000
Submitted job: 2018-12-11_21_02_29
Console: https://console.cloud.google.com/dataflow/job/2018-12-11...
Logs: https://console.cloud.google.com/logs/viewer?job_id%2F2018-12-11...
Job state: JOB_STATE_PENDING …
Job still running …
Job still running …
...
Job succeeded!
Let’s take a moment to explain what’s going on, starting with the various flags. The --runner dataflow flag tells the Apache Beam SDK to run this on GCP Dataflow, including executing all the steps required to make that happen. This includes, compiling the code and uploading it to the --staging_location. Later the staged binary will be run by Dataflow under the --project project. As this will be running “in the cloud”, the pipeline will not be able to access local files. Thus for both the --input and --output flags are set to paths on GCS, as this is a convenient place to store files. Finally the --worker_harness_container_image flag specifies the docker image that Dataflow will use to host the workcount.go binary that was uploaded to the --staging_location.
Once wordcount.go is running, it prints out helpful information, such as links to the the Dataflow console. The console displays current progress as well as a visualization of the pipeline as a directed graph. The local wordcount.go continues to run only to display status updates. It can be interrupted at any time, but the pipeline will continue to run on Dataflow until it either succeeds or fails. Once that occurs, the logs link can provide useful information.
Art history (more complex example)
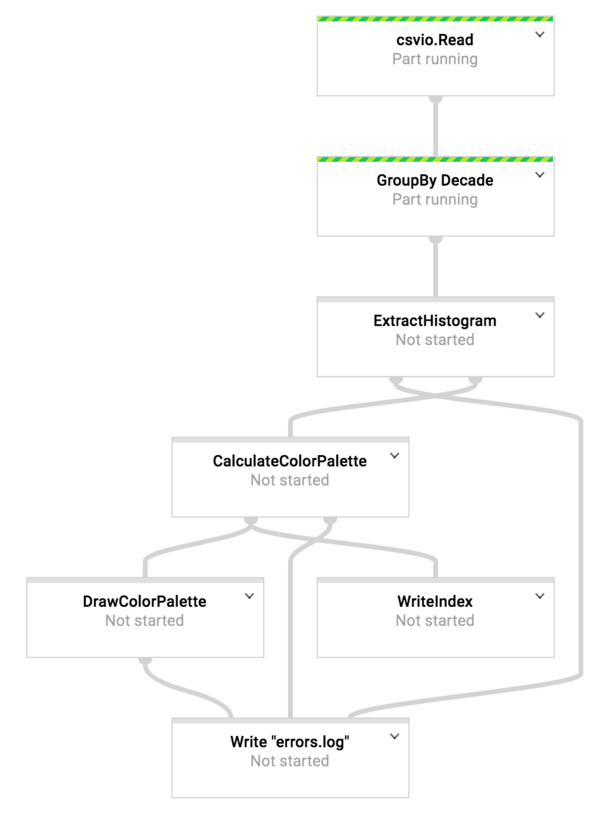
Now we’ll construct a more complex pipeline, that demonstrates some other features of Beam and Dataflow. In this pipeline we will be taking 100,000 paintings from the last 600 years and processing them to extract information about their color palettes. Specifically the question we aim to answer is, “Has the color palettes of paintings change over the decades?”. This may not be a pipeline we run repeatedly, but it was a fun example, and demonstrates many advance topics.
We will skip over the details of the color extraction algorithm, and provide that in a later article. Here we’ll focus on how to create a pipeline to accomplish this task.
We start by reading a csv file that contains metadata for each painting, such as the artist, year it was painted, and a GCS path to a jpg of the painting. The paintings will then be grouped by the decade they were painted, and then the color palette for each group will be determined. Each palette will saved to a png file (DrawColorPalette), as well as all the palette saved to a single large json file (WriteIndex). To finish it off, the pipeline will be productionised, so it easier to debug, and re-run. The full source code is available here.
To start with, the main function for the pipeline looks like this:
import (
...
"github.com/apache/beam/sdks/go/pkg/beam"
...
)
func main() {
// If beamx or Go flags are used, flags must be parsed first.
flag.Parse()
// beam.Init() is an initialization hook that must called on startup. On
// distributed runners, it is used to intercept control.
beam.Init()
p := beam.NewPipeline()
s := p.Root()
buildPipeline(s)
ctx := context.Background()
if err := beamx.Run(ctx, p); err != nil {
log.Fatalf(ctx, "Failed to execute job: %v", err)
}
}
That is the standard boilerplate for a Beam pipeline, it parses the flags, initialises Beam, delegates the pipeline construction to buildPipeline function, and finally runs the pipeline.
The interesting code begins in the buildPipeline function, which constructs the pipeline, by passing PCollections from one function to the next. To build up the tree we see in the above diagram.
func buildPipeline(s beam.Scope) {
// nothing -> PCollection<Painting>
paintings := csvio.Read(s, *index, reflect.TypeOf(Painting{}))
// PCollection<Painting> -> PCollection<CoGBK<string, Painting>>
paintingsByGroup := GroupByDecade(s, paintings)
// PCollection<CoGBK<string, Painting>> ->
// (PCollection<KV<string, Histogram>>, PCollection<KV<string, string>>)
histograms, errors1 := ExtractHistogram(s, paintingsByGroup)
// Calculate the color palette for the combined histograms.
// PCollection<KV<string, Histogram>> ->
// (PCollection<KV<string, []color.RGBA>>, PCollection<KV<string, string>>)
palettes, errors2 := CalculateColorPalette(s, histograms)
// PCollection<KV<string, []color.RGBA>> -> PCollection<KV<string, string>>
errors3 := DrawColorPalette(s, *outputPrefix, palettes)
// PCollection<KV<string, []color.RGBA>> -> nothing
WriteIndex(s, morebeam.Join(*outputPrefix, "index.json"), palettes)
// PCollection<KV<string, string>> -> nothing
WriteErrorLog(s, "errors.log", errors1, errors2, errors3)
}
To make it easy to follow, each function describes the step, and is annotated with a comment that explains what kind of PCollection is accepted and returned. Let’s highlight some interesting steps.
var (
index = flag.String("index", "art.csv", "Index of the art.")
)
// Painting represents a single painting in the dataset.
type Painting struct {
Artist string `csv:"artist"`
Title string `csv:"title"`
Date string `csv:"date"`
Genre string `csv:"genre"`
Style string `csv:"style"`
Filename string `csv:"new_filename"`
...
}
...
func buildPipeline(s beam.Scope) {
// nothing -> PCollection<Painting>
paintings := csvio.Read(s, *index, reflect.TypeOf(Painting{}))
...
The very first step uses csvio.Read to read the CSV file specified by the --index flag, and returns a PCollection of Painting structs. In all the examples we’ve seen before the PCollections only contains basic types, e.g. strings, ints, etc. More complex types, such as a slices and structs are allowed (but not maps and interfaces). This makes it easier to pass rich information between the PTransforms. The only caveat is the type must be JSON-serialisable. This is because in a distributed pipeline, the PTransforms could be processed on different machines, and the PCollection needs to be marshalled to be passed between them.
For Beam to successfully unmarshal your data, the types must also be registered. This is typically done within the init() function, by called beam.RegisterType.
func init() {
beam.RegisterType(reflect.TypeOf(Painting{}))
}
If you forget to register the type, a error will occur at Runtime, for example:
java.util.concurrent.ExecutionException: java.lang.RuntimeException: Error received from SDK harness for instruction -224: execute failed: panic: reflect: Call using main.Painting as type struct { Artist string; Title string; ... } goroutine 70 [running]:
This can be a little frustrating, as when running the pipeline locally with the direct runner, it does not marshal your data, so errors like this aren’t exposed until running on Dataflow.
Now we have a collection of Paintings, we group them by decade:
// GroupByDecade takes a PCollection<Painting> and returns a
// PCollection<CoGBK<string, Painting>> of the paintings group by decade.
func GroupByDecade(s beam.Scope, paintings beam.PCollection) beam.PCollection {
s = s.Scope("GroupBy Decade")
// PCollection<Painting> -> PCollection<KV<string, Painting>>
paintingsWithKey := morebeam.AddKey(s, func(art Painting) string {
return art.Decade()
}, paintings)
// PCollection<string, Painting> -> PCollection<CoGBK<string, Painting>>
return beam.GroupByKey(s, paintingsWithKey)
}
The first line in this function, s.Scope("GroupBy Decade") allows us to name this step, and group multiple sub-steps. For example, in the above diagram “GroupBy Decade” is a single step, which can be expanded to show a AddKey and GroupByKey step.
GroupByDecade returns a PCollection<CoGBK<string, Painting>>. The CoGBK, is short for Common Group By Key. It is a special collection, where (as you’ll see later) each element is a tuple of a key, and an iterable collection of elements. The key in this case is the decade the painting was painted. The PCollection<Painting> is transformed into a PCollection<KV<String,Painting>> by the morebeam.AddKey step, adding a key to each value. Then the GroupByKey will use that key to produce the final PCollection.
Next up is the ExtractHistogram, which takes the PCollection<CoGBK<string, Painting>>, and returns two PCollections. The first PCollection is a PCollection<KV<string, Histogram>>, which contains a color histogram for every decade of paintings. The second PCollection is related to error handling, and will be explained later.
The ExtractHistogram function demonstrates three new concepts, “Stateful functions”, “Data enrichment”, and “Error handling”.
Stateful functions
var (
artPrefix = flag.String("art", "gs://mybucket/art", "Path to where the art is kept.")
)
func init() {
beam.RegisterType(reflect.TypeOf((*extractHistogramFn)(nil)).Elem())
}
type extractHistogramFn struct {
ArtPrefix string `json:"art_prefix"`
fs filesystem.Interface
}
// ExtractHistogram calculates the color histograms for all the Paintings in
// the CoGBK.
func ExtractHistogram(s beam.Scope, files beam.PCollection)
(beam.PCollection, beam.PCollection) {
s = s.Scope("ExtractHistogram")
return beam.ParDo2(s, &extractHistogramFn{
ArtPrefix: *artPrefix,
}, files)
}
Instead of passing a simple function to beam.ParDo, a struct containing two fields is passed. The exported field, ArtPrefix is the path to where the painting jpgs are stored, and the unexported field, fs, is a filesystem client for reading these jpgs.
When the pipeline runs, no global variables are allowed, including the command line flag variables. For example, when running this pipeline we may start it like so:
go run main.go \
--art gs://${BUCKET?}/art/ \
--runner dataflow \
...
When the code actually runs on the Dataflow workers, the --art flag is not specified. Thus the *artPrefix value will use the default value. To pass this to the Dataflow workers, it must be part of the DoFn struct that is passed to beam.ParDo. So in this example, we create a extractHistogramFn struct, with the exported ArtPrefix field set to the value of the --art flag. This extractHistogramFn is then marshalled and passed to the workers. As with the unmarshalled PCollection values, the extractHistogramFn must also be registered with beam during init.
When the pipeline executes this step it calls the extractHistogramFn’s ProcessElement method. This method works in a similar way to a simple DoFn functions. The arguments and return value are reflected at runtime and mapped to the PCollections being processed and returned.
Iterating over a CoGBK
func (fn *extractHistogramFn) ProcessElement(
ctx context.Context,
key string, values func(*Painting) bool,
errors func(string, string)) HistogramResult {
log.Infof(ctx, "%q: ExtractHistogram started", key)
var art Painting
for values(&art) {
filename := morebeam.Join(fn.ArtPrefix, art.Filename)
h, err := fn.extractHistogram(ctx, key, filename)
if err != nil {
…
}
result.Histogram = result.Histogram.Combine(h)
}
return result
}
ProcessElement is called once for every unique group in the PCollection<CoGBK<string, Painting>. The key string argument will be the key for that group, and a values func(*Painting) bool is used to iterate all values within the group. The contact is that values is passed a pointer to a Painting struct, which is populated on each iteration. As long as there are more paintings to process in the group the values function returns true. Once it returns false, the group has been fully processed. This iterator pattern is unique to the CoGBK and makes it convient to apply an operation to every element in the group.
In this case, extractHistogram is called for each Painting, fetches a jpg of the artwork, and extract a [histogram of colors]((https://en.wikipedia.org/wiki/Color_histogram). The histograms from all painting in that group are combined, and finally one result is per group is returned.
Data enrichment
Reading the paintings from an external service (such as GCS) demonstrates a data enrichment step. This is where an external service is used to “enrich” the dataset the pipeline is processing. You could imagine a user service being called when processing log entries, or a product service when processing purchases. It should be noted, that any external action should be idempotent. If a worker fails, it is possible the same element is retried, and thus processed multiple times. Dataflow keeps track of failures and ensures the final result only has each element processed once.
When calling a remote service, typically some kind of client is needed to make the request. In this pipeline we read the images from GCS, thus setting up GCS client at startup is useful. Since we are using a struct based DoFn, there are some additional methods that can be defined.
func (fn *extractHistogramFn) Setup(ctx context.Context) error {
var err error
fn.fs, err = filesystem.New(ctx, fn.ArtPrefix)
if err != nil {
return fmt.Errorf("filesystem.New(%q) failed: %s", fn.ArtPrefix, err)
}
return nil
}
func (fn *extractHistogramFn) Teardown() error {
return fn.fs.Close()
}
When the DoFn is initialized on the worker, the Setup method is called. Here a new Filesystem client is created and store it in the struct’s fs field. Later, when the DoFn is no longer needed, the Teardown method is called, giving us opportunity to cleanup the client. With all things distributed, don’t expect the Teardown to ever be called.
There are also some simple best practices around error handling that should be following when calling an external services.
func (fn *extractHistogramFn) extractHistogram(ctx context.Context,
key, filename string) (palette.Histogram, error) {
ctx, cancel := context.WithTimeout(ctx, 30*time.Second)
defer cancel()
fd, err := fn.fs.OpenRead(ctx, filename)
if err != nil {
return nil, fmt.Errorf("fs.OpenRead(%q) failed: %s", filename, err)
}
defer fd.Close()
img, _, err := image.Decode(fd)
if err != nil {
return nil, fmt.Errorf("image.Decode(%q) failed: %s", filename, err)
}
return palette.NewColorHistogram(img), nil
}
The function begins by using a context.WithTimeout. This ensures that if the external service does not respond in a timely manner the context will be cancelled and a error returned. If this timeout wasn’t set, the external call may never end, and the pipeline never terminates.
Since the pipeline could be running across 100s of machines, it could generate significant load on a remote service. It is wise to implement appropriate backoff and retry logic. In some cases even rate limiting your pipeline’s execution, or tagging your pipeline’s traffic at a lower QoS so it can be easily shed.
The external service, may also return permanent errors. Thus a more robust error handling pattern is needed.
Error handling and dead letters
When Beam processes a PCollection, it bundles up multiple elements and processes one bundle at a time. If the PTransform return an error, panics, or otherwise fails (such as running out of memory), the full bundle is retried. With Dataflow, bundles are retried up to four times, after which the entire pipeline is aborted. This can be inconvenient, so where appropriate instead of returning an error we we use a dead letter queue. This is a new PCollection that collects processing errors. These errors can then be persisted at the end of the pipeline, manually inspected, and processed again later.
return beam.ParDo2(s, &extractHistogramFn{
ArtPrefix: *artPrefix,
}, files)
A keen observer would have noticed that beam.ParDo2 was used by ExtractHistogram, instead of beam.ParDo. This function works the same, but returns two PCollections. In our case, the first is the normal output, and the second is a PCollection<KV<string, string>>. This second collection is keyed on the unique identifer of the painting having an issue, and the value is the error message.
Since returning a error is optional, the errors PCollection was passed to extractHistogramFn’s ProcessElement as a errors func(string, string).
Throughout we use this kind of error PCollections from every stage, and at the end of the pipeline they are collected together and output to a single errors log file:
// WriteErrorLog takes multiple PCollection<KV<string,string>>s combines them
// and writes them to the given filename.
func WriteErrorLog(s beam.Scope, filename string, errors ...beam.PCollection) {
s = s.Scope(fmt.Sprintf("Write %q", filename))
c := beam.Flatten(s, errors...)
c = beam.ParDo(s, func(key, value string) string {
return fmt.Sprintf("%s,%s", key, value)
}, c)
textio.Write(s, morebeam.Join(*outputPrefix, filename), c)
}
Since the output is key, comma, value, the file can easily be re-read to try just the failed keys.
The rest of the pipeline is much of the same, and thus won’t be explained in detail. CalculateColorPalette takes the color histograms and runs a K-Means clustering algorithm to extract the color palettes for those paintings. Those palettes are written out to png files with the DrawColorPalette, and finally all the palettes are written out to a JSON file in WriteIndex.
Gotchas
Marshing
Always remember to register the types that will be transmitted between workers. This is anything that’s inside a PCollection, as well as any DoFn. Not all types are allowed, but slices, structs, and primitives are. For other types, custom JSON marshalling can be used.
It should also be reminded that global state is not allowed. Flags and other global variables will not always be populated when running on a remote worker. Also, examples like this may catch you out:
prefix := “X”
s = s.Scope(“Prefix ” + prefix)
c = beam.ParDo(s, func(value string) string {
return prefix + value
}, c)
This simple example appears to add “X” to the beginning of each element, however, it will prefix nothing. This is because, the simple anonymous function is marshalled, and unmarshalled on the worker. When it is then invoked on the worker, it does not have the closure, and thus has not captured the value of prefix. Instead prefix is the zero value. For this example to work, prefix must be defined inside the anonymous function, or a DoFn struct used which contains the prefix as a marshalled field.
Errors
Since the pipeline could be running across 100s of workers, errors are to be expected. Extensively using log.Infof, log.Debugf, etc will make your live better. They can make it very easy to debug why the pipeline got stuck, or mysteriously failed.
While debugging this pipeline, it would occasionally fail due to exceeding the memory limits of the Dataflow worker’s. Standard Go infrastructure can be used to help debug this, such as pprof.
import (
"net/http"
_ "net/http/pprof"
)
func main() {
...
go func() {
// HTTP Server for pprof (and other debugging)
log.Info(ctx, http.ListenAndServe("localhost:8080", nil))
}()
...
}
This configures a webserver which can export useful stats, and used for grabbing pprof profiling data.
Difference between direct and dataflow runners
Running the pipeline locally is a quick way to validate the pipeline is setup, and that is runs as expected. However, running locally won’t run the pipeline in parallel, and it is obviously constrained to a single machine. There are some other difference, mostly around marshalling data. It’s always a good idea to test on Dataflow, perhaps with a smaller or sampled dataset as input, that can be used as a smoke test.
Conclusion
This article has covered the basics of creating an Apache Beam pipeline with the Go SDK, while also covering some more advanced topics. The results of the specific pipeline will be revealed in a later article, until then the code is available here.
While the Beam Go SDK is still experimental, there are many great tutorials and example using the more mature Java and Python Beam SDKs [1, 2]. Google themselves even published a series of generic articles [part 1, part 2] explaining common use cases.